Retrieval - Document Loaders
RAG(Retrieval-Augmented Generation)란
외부 데이터를 참조하여 LLM이 답변할 수 있도록 해주는 프레임 워크

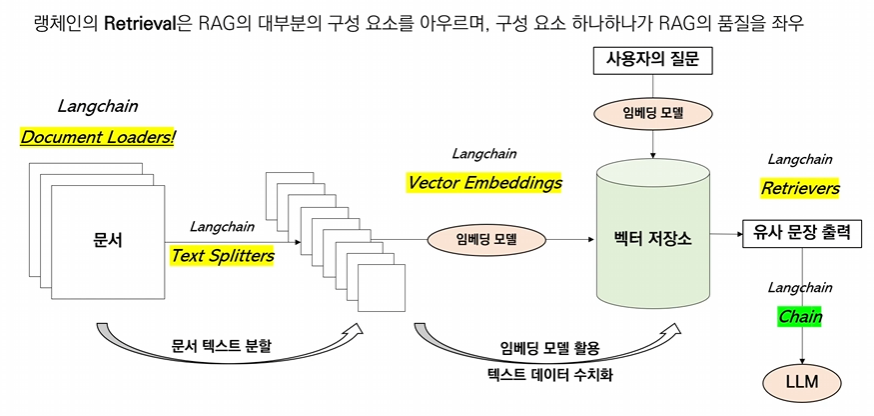
Document Loaders는 다양한 형태의 문서를 RAG 전용 객체로 불러들이는 모듈
- Page_content : 문서의 내용
- Metadata : 문서의 위치, 제목, 페이지 넘버 등
URL Document Loader (WebBaseLoader, UnstructuredURLLoader)
- WebBaseLoader
# !pip install langchain pypdf unstructured pdf2image docx2txt pdfminer
# pip install -U langchain-community
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("<https://n.news.naver.com/mnews/article/092/0002307222?sid=105>")
data = loader.load()
print(data[0].page_content)- UnstructuredURLLoader
# !pip install pdfminer.six
from langchain.document_loaders import UnstructuredURLLoader
urls = [
"<https://n.news.naver.com/mnews/article/092/0002307222?sid=105>",
"<https://n.news.naver.com/mnews/article/052/0001944792?sid=105>",
]
loader = UnstructuredURLLoader(urls=urls)
data = loader.load()
data
PDF Document Loader (PyPDFLoader)
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content/drive/MyDrive/LLM자료/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf의 사본.pdf")
pages = loader.load_and_split()
print(pages[1].page_content)
Word Document Loader (Docx2txtLoader)
# !pip install docx2txt
from langchain.document_loaders import Docx2txtLoader
loader = Docx2txtLoader("/content/drive/MyDrive/LLM자료/해커톤.docx")
data = loader.load()
print(data)
print(data[0].metadata)
print(data[0].page_content)
CSV Document Loader
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='/content/drive/MyDrive/basketball.csv', csv_args={
'delimiter': ',',
'quotechar': '"',
'fieldnames': ['ID', 'Name', 'Position', 'Height', 'Weight', 'Sponsorship Earnings', 'Shoe Sponsor', 'Career Stage', 'Age']
})
data = loader.load()
data[:10]
'LLM > LLM 공부' 카테고리의 다른 글
| Retrieval-Text Embeddings (0) | 2025.03.07 |
|---|---|
| Retrieval - Text Splitters (0) | 2025.03.07 |
| PromptTemplate에 대해 (0) | 2025.03.07 |
| ChatGPT API 실습 (0) | 2025.03.07 |
| LangChain의 개념 (0) | 2025.03.07 |

